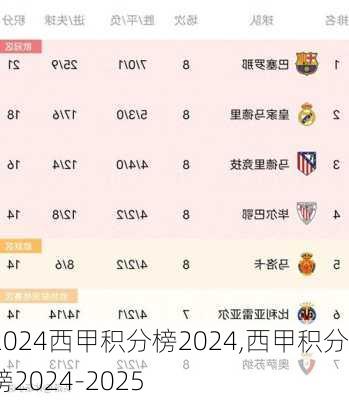
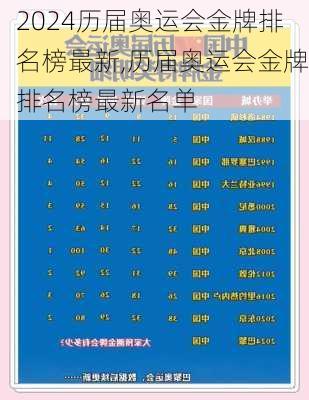
AUC高Accuracy低的原因分析
AUC(Area
Under
Curve)和Accuracy是机器学习中常用的评价指标,它们在一定程度上反映了模型的性能,但有着不同的含义和应用场景。AUC代表的是分类或者排序能力,它是ROC曲线下的面积,取值范围在0.5到1之间,数值越大,对应的分类器越好。Accuracy则是指预测正确的样本占总样本的比例,它受到分类阈值的影响,也就是说,同一个模型在不同的阈值下可能会取得不同的Accuracy。
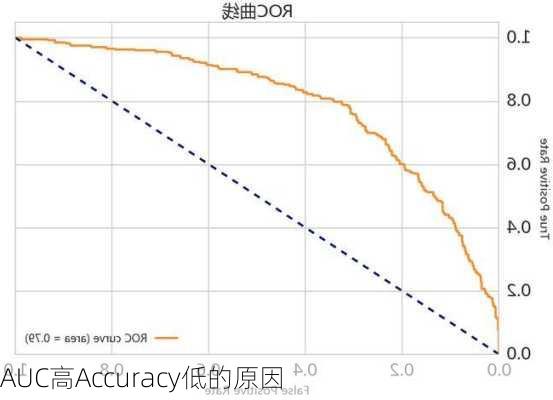
AUC高通常意味着模型能够很好地区分正负样本,即使在样本分布极不平衡的情况下也能取得较好的分类效果。这可能是因为模型找到了样本之间的有效区分特征,使得正负样本在特征空间中的分布差异较大。在这种情况下,即使误判的部分样本数量较多,但由于总体上正负样本可以有效区分,因此AUC值仍然较高。
Accuracy低可能是由于模型的决策阈值设置不当,导致正样本和负样本的预测结果出现了较大的偏差。例如,如果模型在预测过程中倾向于将所有样本预测为负类,那么Accuracy将会非常高,但这种情况下模型的分类能力较弱,因为正样本被大量错误地预测为负样本。此外,如果样本中正负样本的数量差距过大,那么即使模型对少数正样本的预测出现了较多错误,但由于多数负样本的预测是正确的,Accuracy仍然会保持在一个较高的水平。
综上所述,AUC高Accuracy低的情况可能出现在以下几种情况下:
模型的决策阈值设置不当,导致正样本和负样本的预测结果出现了较大的偏差;
样本中正负样本的数量差距过大,即使模型对少数正样本的预测出现了较多错误,Accuracy仍然保持在一个较高的水平;
模型能够很好地区分正负样本,即使在样本分布极不平衡的情况下也能取得较好的分类效果。
在实际应用中,应根据具体的问题和需求选择合适的评价指标。如果希望模型在区分正负样本方面表现优秀,即使牺牲一定的Accuracy也在所不惜,那么AUC将是更好的选择。反之,如果非常看重模型的整体预测准确性,那么调整决策阈值或处理样本不平衡问题将是提高Accuracy的有效途径。