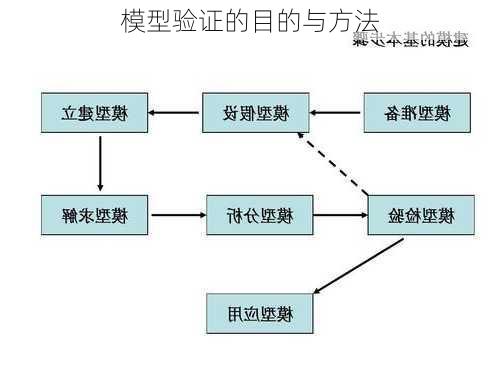
模型验证的目的
模型验证的主要目的是测定标定后的模型对未来数据的预测能力,即可信程度。由于预测的规划年数据不可能在现场得到,就需要借用现状或过去的观测值来进行验证。模型验证不仅关注模型的预测准确性,还涉及到模型设计的合理性、开发过程和结果的有效性、稳定性,以及模型是否符合业务逻辑、是否符合监管要求等因素。
模型验证的方法
1.灵敏度分析与拟合度分析
灵敏度分析和拟合度分析是两种常用的模型验证方法。灵敏度分析着重于确保模型预测值不会背离期望值,如相差太大,则可判断应调整模型。拟合度分析则是类似于模型标定的过程,主要用于校核观测值和预测值的吻合程度。
2.交叉验证
交叉验证是一种常用的模型验证方法,它通过重复使用数据,将建模样本数据集进行拆分,然后组合成不同的训练集和测试集,在训练集中训练模型,在测试集中评价模型。常见的交叉验证方法包括HoldOut交叉验证、KFold交叉验证、分层KFold交叉验证、ShuffleSplit交叉验证和LeavePOut交叉验证等。
HoldOut交叉验证:将整个数据集按照一定比例随机划分为训练集和验证集。这种方法是最基础的也是最简单的交叉验证方法,但由于在每次构建模型过程中,模型训练集上仅拟合一次,因此任务执行速度很快,但为了保证模型相对稳定,往往可以多次对数据进行拆分并训练模型,最后从中选择性能表现较优模型。
KFold交叉验证:将整个样本数据集拆分为K个相同大小的子样本,每个分区样本可以称为一个“折叠”,因此拆分后的样本数据可理解为K折。其中,某任意1折数据作为验证集,而其余K1折数据相应作为作训练集。模型训练后的最终精度评估,可以通过取K个模型在对应验证数据集上的平均精度。
分层KFold交叉验证:主要原理逻辑与K折交叉验证是类似的,仍然是将整个样本数据集拆分为K个部分,最关键的区别是分层K折交叉验证通过对目标变量的分层抽样,使得每个折叠数据集的目标变量分布比例,与整个样本数据的目标情况保持一致,有效解决样本不均衡的情况,因此是K折交叉验证的优化版,且更能满足实际业务场景的需求。
ShuffleSplit交叉验证:这种方法同样采用了样本数据随机拆分的思想,但实现过程主要有两个优点,一个是可以自由指定训练集与验证集的样本量大小,另一个是可以定义循环验证的重复次数n,相比K折交叉验证的固定K次重复明显更为灵活。
3.数据与业务逻辑验证
除了上述技术层面的验证方法,更重要的是对模型的业务逻辑进行验证,确认所建立的模型是否符合业务场景、应用客群。例如,入选的变量是否在该业务流程中能够采集到真实准确的数据、目标客群是否与建模时的开发样本客群保持一致等。
4.定性和定量验证过程
定性验证主要是确保定量方法合适的使用,获取违约概率,评级系统的完整性、客观性、可接受性和一致性,以及数据质量的验证等。定量验证包括评级验证过程、统计指标的计算过程、基于经验数据的解释等。
5.混淆矩阵与ROC曲线
通过混淆矩阵可以算出模型预测精度、正例覆盖率、负例覆盖率等指标,从而综合考虑模型的预测准确率。ROC曲线则是通过Sensitivity(正确预测到的正例数/实际正例总数)和Specificity(正确预测为负的负例数/实际负例总数)来评估模型的性能。
以上各种方法各有优缺点,适用于不同的场景和需求。在实际应用中,可以根据具体情况选择合适的方法进行模型验证。