模型选择的流程图
在构建和选择合适的模型时,有几个关键步骤需要注意。以下是基于搜索结果的模型选择流程图概述:
1.数据集划分
首先,需要将原始数据集划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于模型选择,而测试集用于评估最终模型的泛化性能。这个步骤的目标是确保模型能够在未见过的数据上表现良好。
2.模型训练与验证
在这个阶段,使用训练集对不同的模型进行训练,并在验证集上评估每个模型的性能。这可以通过交叉验证技术实现,如K折交叉验证(CV)或自助采样法(bootstrapping)。这些方法可以帮助我们了解模型在不同数据子集上的表现,并选择具有最佳性能的模型。
3.学习曲线与凸性假设
基于学习曲线的交叉验证(LCCV)方法是一种改进的模型选择方法。它通过在不同大小的训练子集上评估候选模型,结合学习曲线的曲率与凸性假设,可以在较短的时间内评估多个数据子集的模型,并提供有关候选模型学习行为的洞见。
4.模型评估与剪枝
在完成模型选择后,需要使用测试集对最终选定的模型进行评估,以确保其对未知数据的泛化能力。如果候选模型的学习曲线是凸的,那么LCCV将在候选模型不太可能成为最优解时提前剪枝,从而节省计算资源。
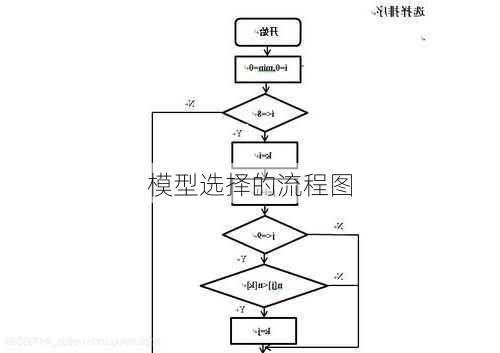
5.模型部署与监控
一旦选择了最佳模型,就可以将其部署到实际环境中。为了确保模型在实际环境中的持续有效,还需要定期监控模型的性能,并在必要时进行更新和维护。
以上就是基于搜索结果的模型选择流程图概述。请注意,实际流程可能会根据具体的应用场景和需求进行调整。