
协同过滤与其他推荐算法对比
协同过滤(Collaborative
Filtering)是一种常用的推荐算法,其主要思想是根据用户过去的行为和偏好,找到与该用户兴趣相似的其他用户或物品,从而推荐出该用户可能感兴趣的其他物品。以下是协同过滤与其他几种推荐算法的对比。
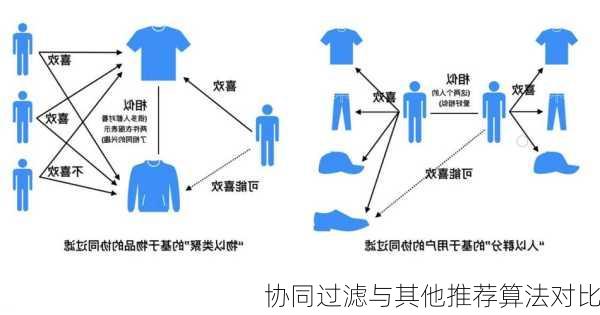
基于用户的协同过滤(Userbased
Collaborative
Filtering)
基于用户的协同过滤是最常见的协同过滤算法之一。它的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,然后基于这K个邻居的历史偏好信息,为当前用户进行推荐。例如,如果用户A和用户C都喜欢物品A和C,那么当用户A对物品B没有评价时,可以根据用户C的喜好来推荐物品B给用户A。
基于物品的协同过滤(Itembased
Collaborative
Filtering)
基于物品的协同过滤则是根据所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。例如,如果用户A喜欢物品A和物品C,用户B喜欢物品A和物品B,用户C喜欢物品A和物品C,那么可以认为物品A和物品C是相似的,因此可以将物品C推荐给喜欢物品A的用户C。
基于内容的推荐(Contentbased
Recommendation)
基于内容的推荐算法则是根据用户过去的喜好历史数据,以及物品本身的特性来进行推荐。例如,在电影推荐系统中,可以通过分析电影的类型、导演、演员等元数据信息,来发现电影之间的相似度,并基于这些相似度来推荐电影。
基于人口统计学的推荐(Demographicbased
Recommendation)
基于人口统计学的推荐算法则是根据用户的个人信息,如年龄、性别、地理位置等,来计算用户的相似度,并基于这些相似度来进行推荐。
总结
协同过滤算法的优点是可以充分利用集体智慧,推荐的个性化程度较高。但是,它也存在一些问题,如数据稀疏性、用户相似度矩阵维护难度大等。相比之下,基于内容的推荐算法推荐结果直观、易理解,但是受特征提取方法的限制,且训练分类器需要巨大的数据;基于人口统计学的推荐算法简单易实施,但是推荐效果可能过于粗糙,无法很好地建模用户的口味。在选择合适的推荐算法时,需要根据具体的应用场景和需求来决定。







