
模型选择的流程
模型选择是机器学习流程中重要的一步,其目标是帮助我们找到具有最佳预测性能的模型。以下是基于搜索结果的理解,介绍了模型选择的一般流程。
在开始模型选择之前,首先需要理解机器学习问题的通用损失函数,即优化特定分布下的损失。假设空间$D=\{d\mid
d\subset\mathcal{X}\times\mathcal{Y}\}$代表所有潜在的数据集,而模型选择则是找到对特定数据集$d'$表现良好的模型。因此,目标是尽量在验证集上达到最小误差$\arg\min_{a\in
A}\nu(d,a)$的模型$a$。
为了估计每个候选模型的性能,需要选择一个验证函数,将模型映射到性能估计值。常用的验证函数包括K折交叉验证(CV)和Monte
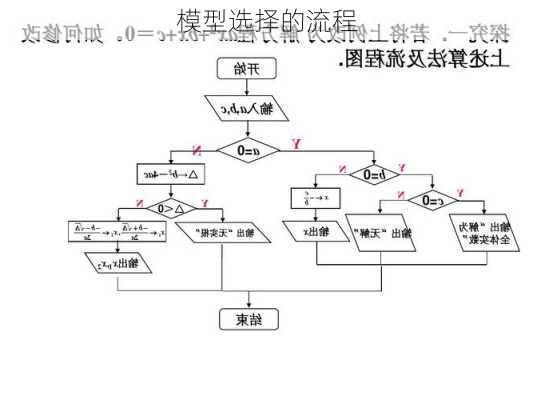
Carlo交叉验证(MCCV)。这些方法的一个问题是它们不能提前丢弃不具备竞争力的候选模型,从而过度浪费了计算资源。
传统的交叉验证方法在评估模型性能时存在一些缺陷,例如不能提前丢弃不具备竞争力的候选模型。为了解决这些问题,学术界最近提出了一种基于学习曲线的交叉验证方法(LCCV),它将候选模型按递增顺序在不同大小的训练子集上进行评估,并通过学习曲线与凸性假设相结合的方式,在候选模型不太可能成为最优解时提前剪枝。
LCCV的主要贡献在于,它将学习曲线与凸性假设相结合,仅在候选模型不太可能成为最优解时提前剪枝。值得一提的是,LCCV是基于模型组合空间生成学习曲线的,这不同于根据交叉验证过程中表现最佳的学习器生成学习曲线,因为基于表现最佳的学习器生成学习曲线不能保证该学习器的性能在不同大小的训练集上都很好。
通过上述流程,我们可以得到多个数据子集上训练模型的验证误差,从而选择具有最佳预测性能的模型。
以上就是模型选择的一般流程。在这个过程中,关键是选择合适的验证函数和评估方法,以便有效地评估和比较不同的候选模型。







