NLP的历史和发展
1.NLP的起源历史
NLP的创立归功于两位美国人,理查德·班德勒(Richard
Bandler)和约翰·格林德(John
Grinder),他们在20世纪70年代初期在美国加州圣地告鲁市大学(University
of
CaliforniaSanta
Cruz)开始了NLP的研究工作。在这个时期,他们发现身、心、语言是互相影响的,而且“卓越”更是可以模仿的。于是深入研究,发现身、心、语言是互相影响的,而且“卓越”更是可以模仿的。于1976年他们决定称这门新学问为NLP,致力将它发扬光大。
2.NLP的发展历程
第一阶段(地上爬):统计机器学习为代表
在word2vec诞生之前,NLP中并没有一个统一的方法去表示一段文本。各位前辈和***们发明了许多的方法,如onehot表示一个词,bagofwords来表示一段文本,textrank中借鉴了pagerank的方法来表征词语的权重,基于SVD纯数学分解词文档矩阵的LSA,pLSA中用概率手段来表征文档形成过程。这一阶段的主要问题是数据稀疏导致的计算为0的现象,基于统计的语言模型无法把n取得很大,一般来说在3gram比较常见,再大的话,计算复杂度会指数上升,统计语言模型无法表征词语之间的相似性。
第二阶段(爬上第一阶梯):word2vec为代表
这一阶段的主要突破是2013年Tomas
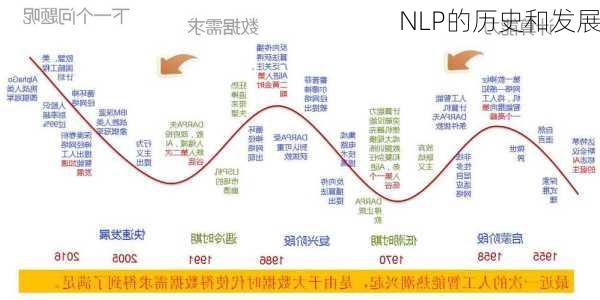
Mikolov提出的word2vec模型,包括CBOW和Skipgram模型。这些模型能够将一个词表征为一个向量形式,从而解决了词语之间的相似性问题。
第三阶段(爬上第二阶梯):BERT为代表
最新的发展阶段是以BERT为代表的模型。BERT使用Transformer的编码器来作为语言模型,并提出了两个新的目标任务(即遮挡语言模型MLM和预测下一个句子的任务)。这些模型在多个NLP任务上取得了最先进的性能。
3.NLP的发展趋势
随着深度学习的发展,神经网络在NLP领域的应用越来越广泛。从最初的统计语言模型,到后来的word2vec,再到现在的BERT,NLP模型的表现不断提升。未来,NLP的发展可能会更加注重模型的解释性和可解释性,同时也可能会有更多的创新模型出现,以应对更复杂的自然语言处理任务。