数据分区的定义
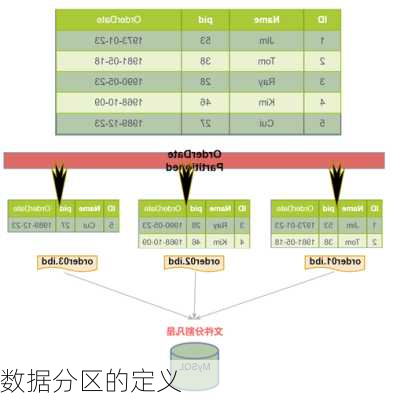
数据分区是分布式数据库中的一个重要概念,它涉及到如何将大规模数据集进行拆分,以便于在多台计算机上进行处理。当数据量非常大时,单机可能无法保存或处理所有数据,因此需要通过数据分区来将不同的数据子集存放到不同的处理节点上。这种对数据进行拆分的方式称为分区。
分区的基本概念分区主要是为了提升系统的可扩展性。通过对大数据集进行分区处理,可以使得查询负载分布在多个处理器上,从而提高查询效率。每个分区由不同的独立、完整的数据库进行保存和处理,然后由一个或多个协调节点进行请求的路由处理。在无共享架构下,分区是当前分布式数据处理系统最常见的一种处理方式。
分区的类型范围分区:根据键做哈希,根据哈希值选择对应的数据节点。范围分区需要依据数据调整分区边界,以实现均匀的数据分布。然而,这种方法可能导致热点问题,即某些分区比其他分区拥有更多的数据或查询负载。散列分区:使用散列函数来确定给定键的分区。散列分区可以实现数据在各个分区之间的均匀分布,但选择合适的散列函数非常重要,否则可能会导致数据分布不均,引发数据倾斜和性能瓶颈。分区的目的
数据分区的主要目的是为了在特定的SQL操作中减少数据读写的总量,从而缩减响应时间。通过分区,可以将表的数据均衡地分布到不同的硬盘或服务器存储介质中,提高数据检索的效率,降低数据库的频繁I/O压力值。
分区与分表、分库的关系分区、分表和分库都是数据库管理系统中用来管理和优化数据的技术。它们的主要区别在于数据分布的粒度和方式。分区是对一张表的数据进行分割,而分表则是将一张表分解成多个具有独立存储空间的实体表。分库则是将整个数据库分成多个部分,每个部分都有自己的数据库服务器。这些技术的目的都是为了提高数据库的性能和可管理性。
综上所述,数据分区是在分布式数据库中将大规模数据集进行拆分的一种方式,它通过将数据分布在不同的处理节点上,提高了系统的可扩展性和查询效率。分区的实现方式和策略多种多样,包括范围分区、散列分区等,目的是为了更好地管理和优化数据。